Using ray.wait to limit the number of pending tasks
TLDR: Use ray.wait to limit the number of pending tasks - pipeline the
execution (opens in a new tab)
by processing the results of completed Ray tasks as soon as they are
available. i.e. Use pipeline execution to process results returned from the
finished Ray tasks using ray.get() and ray.wait()
| Name | Argument Type | Description |
|---|---|---|
ray.get() | ObjectRef or List[ObjectRefs] | Return a value in the object ref or list of values from the object IDs. This is a synchronous (i.e., blocking) operation. |
ray.wait() | List[ObjectRefs] | From a list of object IDs, returns (1) the list of IDs of the objects that are ready, and (2) the list of IDs of the objects that are not ready yet. By default, it returns one ready object ID at a time. However, by specifying num_returns=<value> it will return all object IDs whose tasks are finished and their respective values materialized and available in the object store. |
As we noted in the best practices before, an idiomatic way of using ray.get() is to delay fetching the object until you need them. Another way is to use it is with ray.wait(). Only fetch values that are already available or materialized in the object store. This is a way to pipeline the execution (opens in a new tab), especially when you want to process the results of completed Ray tasks as soon as they are available.
Below is an execution timeline depicting both cases: when using ray.get() to wait for all results to become available before processing them, and using ray.wait() to start processing the results as soon as they become available
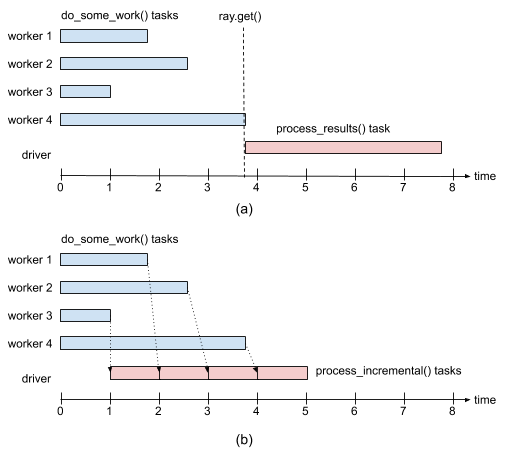
If we use ray.get() on the results of multiple tasks we will have to wait until the last one of these tasks finishes. This can be an issue if tasks take widely different amounts of time.
To illustrate this issue, consider the following example where we run four transform_images() tasks in parallel, with each task taking a time uniformly distributed between 0 and 4 seconds. Next, assume the results of these tasks are processed by classify_images(), which takes 1 sec per result. The expected running time is then (1) the time it takes to execute the slowest of the transform_images() tasks, plus (2) 4 seconds which is the time it takes to execute classify_images().
Let's look at a simple example:
from PIL import Image, ImageFilter
import time
import random
import ray
random.seed(42)
@ray.remote
def transform_images(x):
imarray = np.random.rand(x, x , 3) * 255
img = Image.fromarray(imarray.astype('uint8')).convert('RGBA')
# Make the image blur with specified intensify
img = img.filter(ImageFilter.GaussianBlur(radius=20))
time.sleep(random.uniform(0, 4)) # Mocking this for extra work you need to do.
return img
def predict(image):
size = image.size[0]
if size == 16 or size == 32:
return 0
elif size == 64 or size == 128:
return 1
elif size == 256:
return 2
else:
return 3
def classify_images(images):
preds = []
for image in images:
pred = predict(image)
time.sleep(1)
preds.append(pred)
return preds
def classify_images_inc(images):
preds = [predict(img) for img in images]
time.sleep(1)
return preds
SIZES = [16, 32, 64, 128, 256, 512]Without using ray.wait() and no pipelining, we may do:
start = time.time()
# Transform the images first and then get the images
images = ray.get([transform_images.remote(image) for image in SIZES])
# After all images are transformed, classify them
predictions = classify_images(images)
print(f"Duration without pipelining: {round(time.time() - start, 2)} seconds; predictions: {predictions}")Output:
Duration without pipelining: 8.54 seconds; predictions: [0, 0, 1, 1, 2, 3]Whereas, if we use ray.wait() and pipeline the execution, we may do:
start = time.time()
result_images_refs = [transform_images.remote(image) for image in SIZES]
predictions = []
# Loop until all tasks are finished
while len(result_images_refs):
done_image_refs, result_images_refs = ray.wait(result_images_refs, num_returns=1)
preds = classify_images_inc(ray.get(done_image_refs))
predictions.extend(preds)
print(f"Duration with pipelining: {round(time.time() - start, 2)} seconds; predictions: {predictions}")Which gives us the following output:
Duration with pipelining: 6.45 seconds; predictions: [0, 0, 1, 2, 3, 1]We get some incremental difference. However, for compute intensive and many tasks, and over time, this difference will be in order of magnitude. For large number of tasks in flight, use ray.get() and ray.wait() to implement pipeline execution of processing completed tasks.